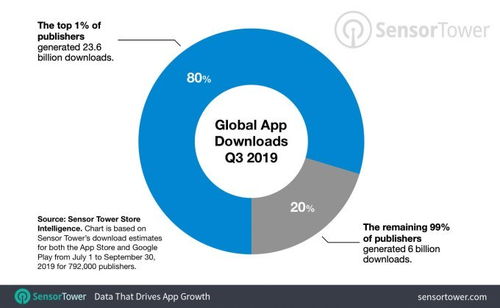
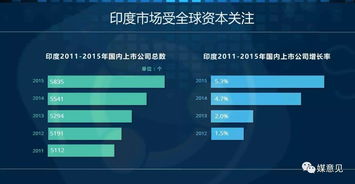
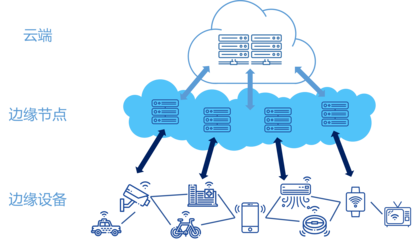
谷歌云宕机风波 网络服务瘫痪敲响灾备警钟

谷歌云服务发生大规模宕机故障,导致YouTube、Gmail、Google Drive等全球数十亿用户依赖的核心服务出现访问中断与功能异常。此次事件不仅暴露了单一云服务商的系统性风险,更将互联网数据服务的灾备与业务连续性管理议题推至聚光灯下。
此次故障持续数小时,波及范围广泛。用户反映视频加载失败、邮件发送延迟、云端文件无法同步等问题,部分企业依托谷歌云运行的应用程序亦陷入停滞。作为全球云计算与数字生态的关键节点,谷歌服务的波动再次印证了现代互联网“牵一发而动全身”的脆弱性——当集中式基础设施出现意外,其涟漪效应可瞬间跨越地域与领域。
深入分析,此次事故凸显出几重警示:其一,超大规模云平台虽通过冗余设计提升可靠性,但复杂的架构与依赖链仍可能存在未被充分识别的单点故障风险;其二,众多企业与开发者将关键业务完全托管于单一云服务商,缺乏跨平台或混合云的灾备方案,一旦主服务异常,业务便面临直接冲击;其三,用户对云端服务的实时性与连续性期待日益增高,任何中断都可能引发信任危机与经济损失。
因此,“灾备业务提上日程”已成为互联网数据服务领域的紧迫课题。企业需重新评估其云战略,从被动响应转向主动规划:一是推行多云或混合云架构,避免“将所有鸡蛋放在一个篮子”,通过技术异构分散风险;二是建立细致的灾难恢复计划(DRP)与业务连续性计划(BCP),明确故障切换流程、数据备份机制与恢复时间目标(RTO);三是加强对云服务商SLA(服务等级协议)的监督与问责,并在合约中明确中断赔偿与应急协作条款。
长远来看,此次事件或将成为行业演进的重要催化剂。具备弹性设计、智能故障转移与实时监控能力的分布式系统将更受青睐;边缘计算、去中心化存储等技术的应用也有望降低对中心化节点的依赖。监管机构可能加强对关键数字基础设施的韧性要求,推动形成更健全的行业标准与协作框架。
谷歌云宕机虽已修复,但其留下的思考深远:在数字化生存日益普及的今天,构建既高效又坚韧的网络服务体系,已不仅是技术挑战,更是关乎社会运转与经济发展的战略命题。唯有将灾备意识深植于互联网服务的基因之中,方能在不可预知的中断面前,守护数字世界的持续稳定与信任。
如若转载,请注明出处:http://www.zivtn.com/product/4.html
更新时间:2026-06-19 08:32:37